In short: AI agent cost optimization starts with context growth. A long-running agent can move from $50 a month to $2,500 because each turn resends system prompts, tool definitions, memory, files, and earlier messages. Four practices bring the bill back under control: prompt caching, lazy-loaded tools, model routing, and context cleanup.
When an agent is new, the system prompt may be only a few hundred tokens, with two or three tools. Then the prompt grows, the tool list expands, memory accumulates, and every turn starts paying for earlier turns. The Claude system prompt leaked in late 2024 was 24,000 tokens, nearly 50 times larger than the starting point. OpenClaw users have reported sending more than 150,000 input tokens to Gemini 3.1 Pro, only to get 29 output tokens in the first turn.
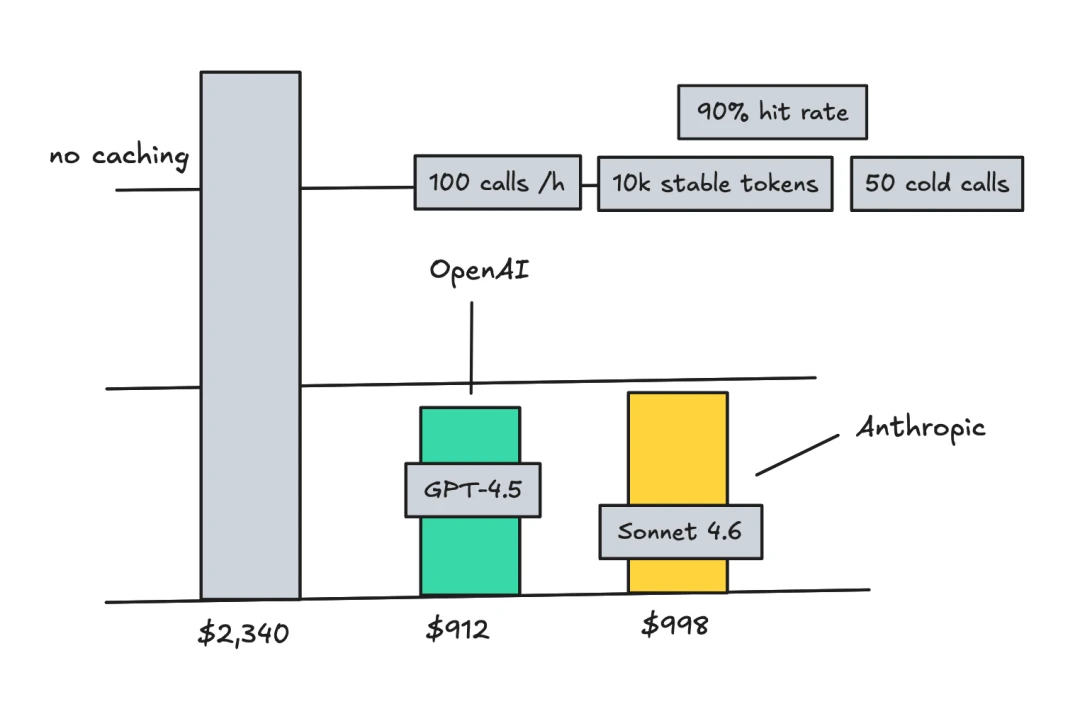
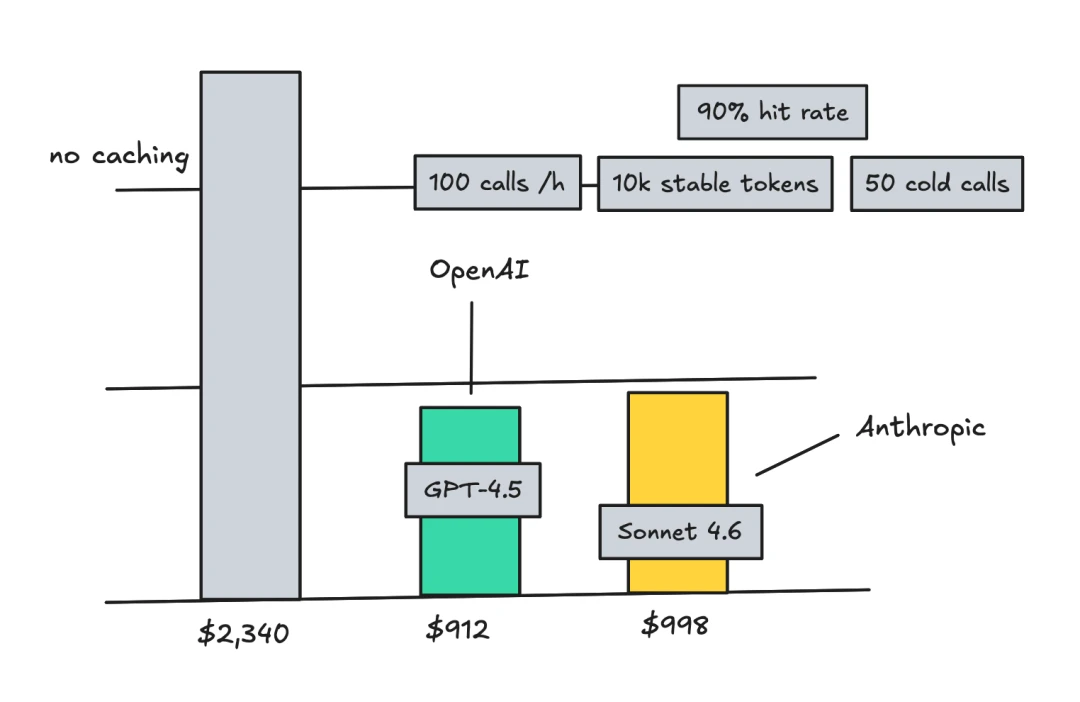
An unoptimized agent handling 100 messages a day with 166K input tokens can cost about $996 a month on Gemini 3.1 Pro and about $2,490 a month on Claude Opus 4.6.
There are ways to push that cost back down to $50-$100 a month.
This is the cost side of the same agent-systems problem behind SkillOpt’s trainable skill files and MUSE-Autoskill’s skill lifecycle. Skills, tools, memory, and routing make agents more capable, but they all compete for the same token budget.
Before getting into the methods, we need to get one premise straight: the cost problem for agents is, at bottom, a context growth problem.
Context: The Bill That Grows With Every Turn
Every request sends the model everything it can “see”: the system prompt, your messages, model replies, referenced files and code, tool definitions, memory, and more. All of that counts as context. The context window is the maximum amount the model can read in one call, measured in tokens. As a rough rule, English is about 3-4 characters per token, while Chinese is about one character per token. Context windows vary a lot by model. Top models such as Claude Opus 4.7, GPT-5.4, and DeepSeek-V4-Pro already support 1M tokens, while Kimi K2.6 supports 256K and MiniMax M2.7 is around 200K.

The key point: context accumulates turn by turn. Every time you send a new message, the previous input and output from all earlier turns are packaged and sent again. The longer the conversation, the more the model has to review, and the more tokens each request contains. That is why an agent’s token bill balloons. You are not just asking more questions. Each new question is dragging a longer history behind it.
Without management, both cost and quality degrade. On cost, agent input tokens usually dwarf output tokens, so most of the bill goes toward “understanding the problem.” On quality, irrelevant material distracts attention, takes space away from useful information, and slows responses.
Once that premise is clear, the four design principles become easier to understand. They all answer the same question: how can we use context more economically?
Four Design Principles
- Reuse tokens whenever possible: prompt caching and semantic cache.
- Do not preload tokens that may never be activated: lean tool definitions and MCP.
- Use cheaper models for cheaper work: routing, cascades, and subagents.
- Keep context clean: context compression and cleanup.
Reuse Tokens Whenever Possible
The cost of an LLM does not only come from calling it too often. It also comes from paying again and again to process the same tokens.
This section covers two very different caching mechanisms: KV cache, which is the mechanism behind prompt caching, and semantic cache. KV caching is a fast win for long system prompts. Semantic cache takes more engineering and carries more risk.
KV Cache and Prefix Cache
Before a model generates anything, it must process the prompt. That work costs compute, latency, and money. So the efficient move is simple: do not process the same content repeatedly.
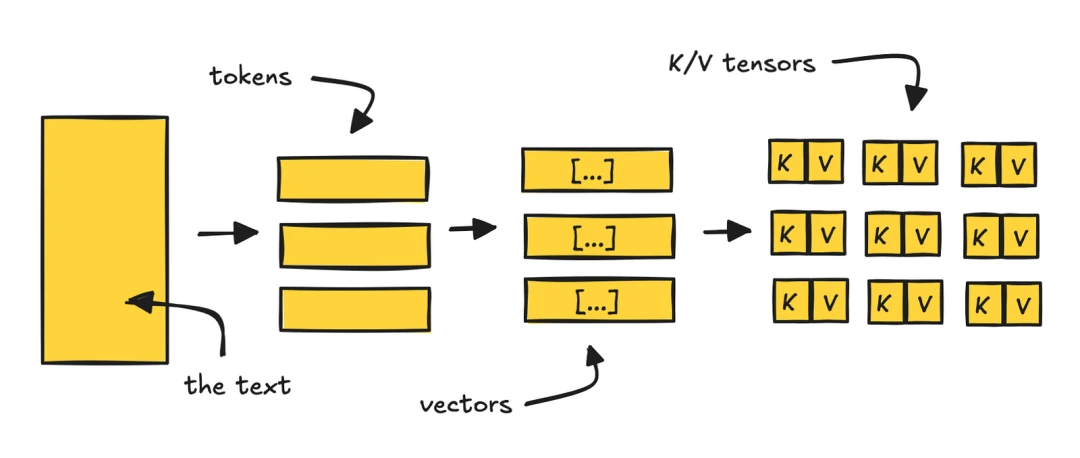
When you use a large language model, the prompt is split into tokens and converted into vectors. Then, inside each attention layer, those vectors are separated into two kinds of tensors: Keys, which act like an index, and Values, which hold the content. Inference engines cache these KV tensors during generation. Without that cache, attention would be too slow to be practical.
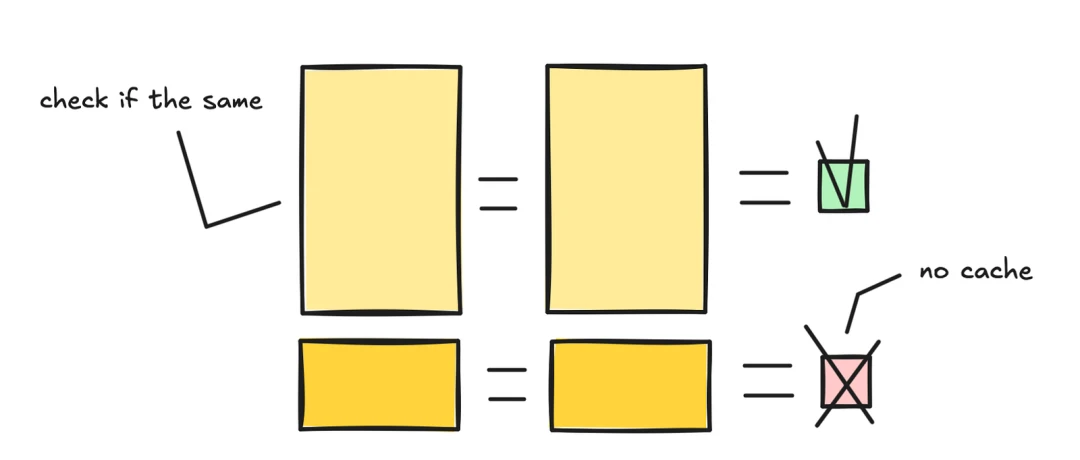
The trick is to keep the cache after the response finishes instead of throwing it away. When the next request comes in, the system checks whether the same prompt prefix already has precomputed tensors. If it does, the system loads them directly and skips recomputation.
Do not underestimate this optimization. In production systems, KV cache hit rate is often treated as one of the most important single metrics for an agent system because it directly affects latency and cost. Some teams even alert on cache hit rate. A few percentage points of misses can materially increase both cost and latency. The reason is straightforward: agent workloads are heavily skewed toward prefill rather than decoding. Manus data shows an average input-to-output token ratio of about 100:1. In other words, 99% of your money goes toward “understanding the problem,” and only 1% goes toward “answering it.”
The cost difference can be huge. Take DeepSeek-V4-Pro as an example. A cache-hit input token costs 0.1 yuan per million tokens. A cache-miss input token costs 12 yuan per million tokens, a 120x difference.
From a context-engineering perspective, improving KV cache hit rate depends on a few practices:
- Keep the prompt prefix stable. Because LLMs are autoregressive, a one-token difference invalidates the cache for everything after that token. A common mistake is putting a timestamp at the start of the system prompt, especially one precise to the second. It lets the model know the current time, but it destroys cache hit rate. Ordering matters too: put the most static material first. A good order is: static system prompt and tool definitions -> project rules -> session context -> conversation messages.
- Append context instead of modifying it. Avoid editing previous actions or observations. Make serialization deterministic. Many languages and libraries do not guarantee stable JSON key order, which can break caching without being obvious. When prompt information becomes stale, such as when time changes or the user edits a file, do not modify the system prompt itself. Insert the update into the next user message or tool result. That communicates the new state while preserving the cached prefix.
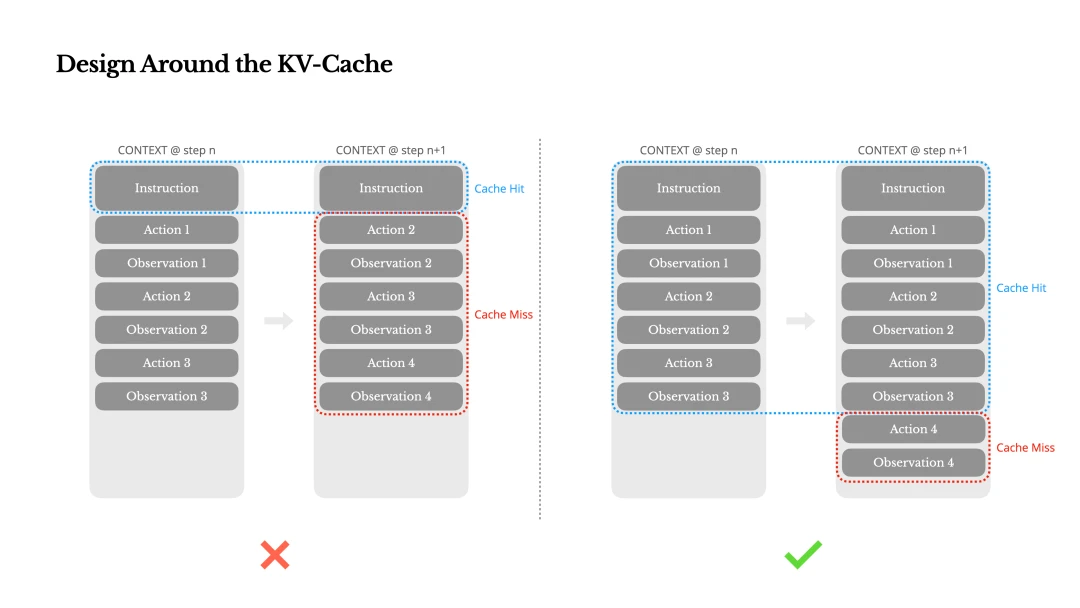
- Mark cache breakpoints explicitly when needed.
Some model providers and inference frameworks do not support automatic incremental prefix caching. In those systems, you need to insert cache breakpoints manually. When assigning breakpoints, consider cache expiration, and at minimum make sure a breakpoint includes the end of the system prompt. If you self-host a model with a framework such as vLLM, make sure prefix caching is enabled, and use techniques such as session IDs to route requests consistently across distributed workers.
The latency benefit is also easy to see. Suppose processing 2,000 tokens takes 1 second and the system prompt is 10,000 tokens. Each LLM call can save 5 seconds just by avoiding repeated computation of the same prompt prefix. Prefill throughput varies by setup, but the principle holds.
There is one catch: the input must match the stored KV cache exactly. Once a token changes, the precomputed KV tensors are invalid and must be rebuilt. People often trip here: an extra space, a different tool-definition order, or a timestamp in the wrong place.
Storing those tensors is not free either. KV cache consumes server memory, so many providers use TTL windows of about 5-10 minutes.
One more detail is easy to miss: caches are model-specific. They are not shared across models. This leads to a counterintuitive result. If you have already cached a 100K-token conversation on Opus and then switch to Haiku for a simple question, it may cost more, because Haiku has to rebuild the whole prompt cache. If you need a cheaper model for subtasks, hand work off to a subagent instead of switching models inside the main session.
Prefix Cache for Self-Hosted Inference
If you host open-source models, you probably use an inference framework such as vLLM. vLLM splits the prompt into blocks, computes hashes from each block’s tokens and preceding tokens, and stores KV tensors under those hashes.
Put static, cacheable material at the very front of the prompt. Enable caching with --enable-prefix-caching, tune block size with --block-size, and set the KV cache memory per GPU explicitly with --kv-cache-memory-bytes. More allocated memory lets cache blocks stay around longer. But if many different long requests run at the same time, memory fills sooner and older blocks are evicted faster.
Other options include SGLang’s RadixAttention prefix cache and LMCache, which can plug into inference engines.
Most people use API providers, and each provider has its own prompt-caching rules.
Prompt Caching Through API Providers
OpenAI: OpenAI requires exact prefix matching, and the same static input must be at the beginning of the prompt. Put stable instructions, examples, and tools first, and variable content later. You can also send prompt-cache-key to help route similar requests to the same cache. Prompt caching is automatically enabled for prompts longer than 1,024 tokens, but the first 256 tokens are used for routing requests to the same cache, so the static section should exceed 256 tokens.
Anthropic: Anthropic requires the cache-control parameter to enable caching. The TTL usually expires after 5-10 minutes of inactivity, but it can be extended to one hour at twice the storage cost.
Cost savings: OpenAI cached input can receive up to a 90% discount. Anthropic also discounts cached input, but you pay for cache storage. Used poorly, Anthropic can become more expensive. In general, if 90% of the prompt is static, correct caching can sharply reduce cost.
Semantic Cache
Semantic cache matches by meaning. If a request is similar enough to a previous one, the system returns the cached result. It sounds simple, but there are many traps.
Semantic matching uses embeddings: text is converted into vectors and compared with cosine similarity. High similarity should mean similar meaning. The idea is to route similar requests to an existing answer. “What is the capital of France?” and “Quickly tell me France’s capital” should hit the same answer.
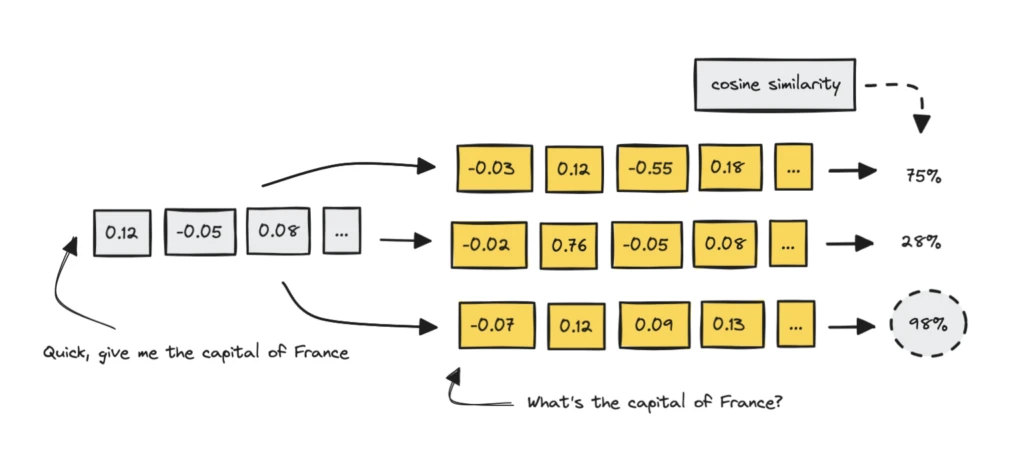
This works well when many users ask nearly identical general questions and the data does not expire quickly. But the open questions add up:
- What similarity threshold should you use?
- How long is an answer valid?
- How do you handle multi-turn conversations?
- What happens if the cached answer is wrong?
- How do you separate context across users?
So even though the mechanism is simple, you still need metadata filters and tags: user, workspace, corpus version, role, session scope, smart TTL, and rules for whether the returned result is good enough. That is real engineering work.
If you do build it, use a semantic index to find previous questions, and allow different questions to point to the same stored answer to reduce storage growth. Manage TTL by usage frequency: keep often-reused items longer and evict the rest. More important, check your logs for repeated patterns first. Your workload may not fit semantic caching at all.
Many tools can help. Databases can support this pattern, and libraries and products include semanticcache, GPTCache, vCache, Upstash semantic-cache, and Redis with LangCache. Redis claims up to 68.8% fewer API calls and 40-50% lower latency, but that data comes from a clear Q&A setting.
Summary: Prompt caching works best when variable questions are embedded inside a large static prompt. Semantic cache works best when people repeatedly ask the same thing in different wording. They can be combined, but do not forget ordinary caching. SQL query results, tool outputs, retrieval results, and other expensive deterministic computations should never run twice unnecessarily.
Do Not Preload Tokens That May Never Be Activated
When the system prompt grows because tool definitions are bloated or memory keeps expanding, it is time to trim it.
Small agents are not the problem. But when tool specifications keep growing, you need ways to slim them down and fetch detail only when needed.
Keep Context Lean and Fetch Detail on Demand
Once an agent prompt grows beyond a certain point, the always-loaded layer should stay as small and stable as possible, with growing details separated elsewhere.
Cost is only the visible problem. Performance suffers too. Loading hundreds of tools, or sending constantly changing MCP server descriptions, makes context noisy. If a layer keeps changing, prompt caching also becomes harder to hit.
The core idea: keep the top layer compact and stable. The top layer helps the model understand “where am I” and “where should I go next,” but it does not need to carry everything from the start.
Claude Code’s memory system follows this pattern: an always-loaded index file stays under 200 lines, while detailed topic files live elsewhere. Claude’s Advanced Tool Search and layered skill setup use a similar idea: lazy-load MCP tools instead of stuffing every server definition into the prompt.
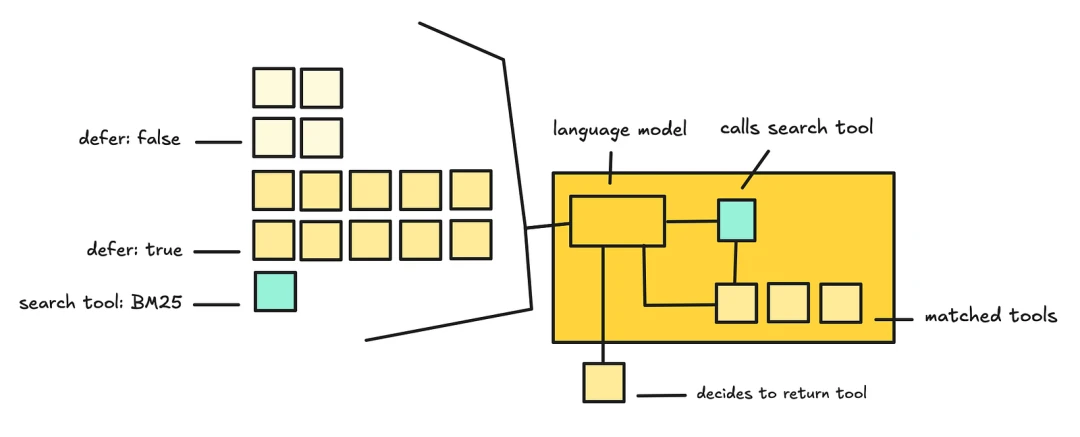
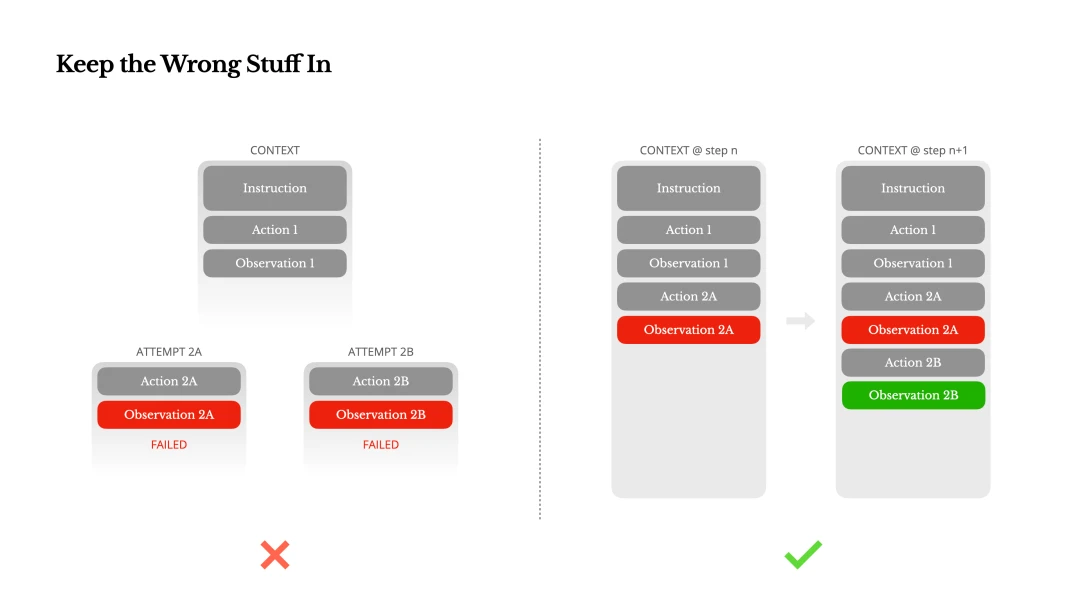
Manus ran into one failure mode: dynamically adding and removing tool definitions looks clever, but in practice it breaks two things:
- In most LLMs, tool definitions are serialized near the front of the context, before or after the system prompt. Any change invalidates the KV cache for all later actions and observations.
- When previous actions and observations still reference tools that are no longer defined in the current context, the model gets confused. This often leads to format violations or hallucinated actions.
The dynamic add/remove pattern is different from lazy loading. Lazy loading retrieves tool definitions when needed and appends them to context without modifying the existing prefix. Dynamic add/remove modifies or removes already-loaded tool definitions during iteration, which breaks the cache. The first is an optimization. The second is a trap.
A better approach is to mask rather than remove. Instead of deleting tool definitions, constrain certain choices during generation so the model can only pick allowed tools. Manus uses a context-aware state machine to manage tool availability, constraining directly at decoding time which actions are allowed.
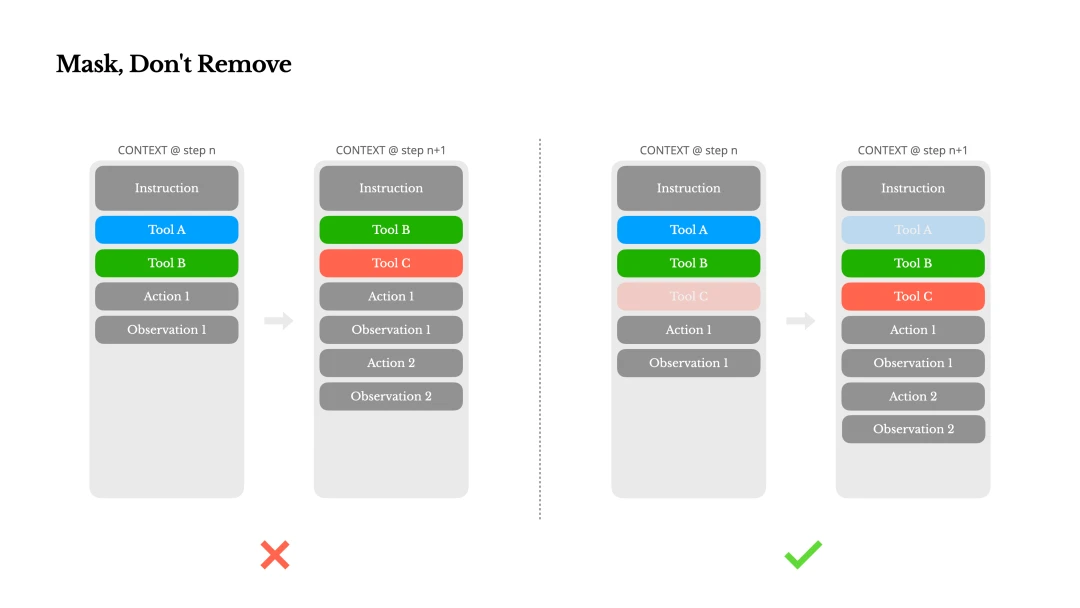
In practice, most model providers and inference frameworks support some form of response prefilling, which lets you constrain the action space without modifying tool definitions. For example, when the user provides new input, the agent may be required to reply immediately instead of taking an action. That can be enforced by prefilling the response prefix. Manus also deliberately designed action names with consistent prefixes, such as browser_ for browser tools and shell_ for command-line tools. This makes it easy to restrict the agent to a specific tool group in a given state, without a stateful logits processor.
Claude Code’s Plan Mode is another classic example. The intuitive approach would be to replace the tool set with read-only tools when the user enters planning mode, but that would break caching. The actual approach keeps all tools present at all times. “Enter plan mode” and “exit plan mode” are tools themselves, and switching mode sends a system message telling the model the current mode and instructions. Tool definitions never change, so the cache stays intact. For cases with too many tools, Claude Code also uses defer_loading: it sends lightweight stubs, only the tool names, and lets the model discover full definitions through tool search when needed.
Practical Effects and Limits
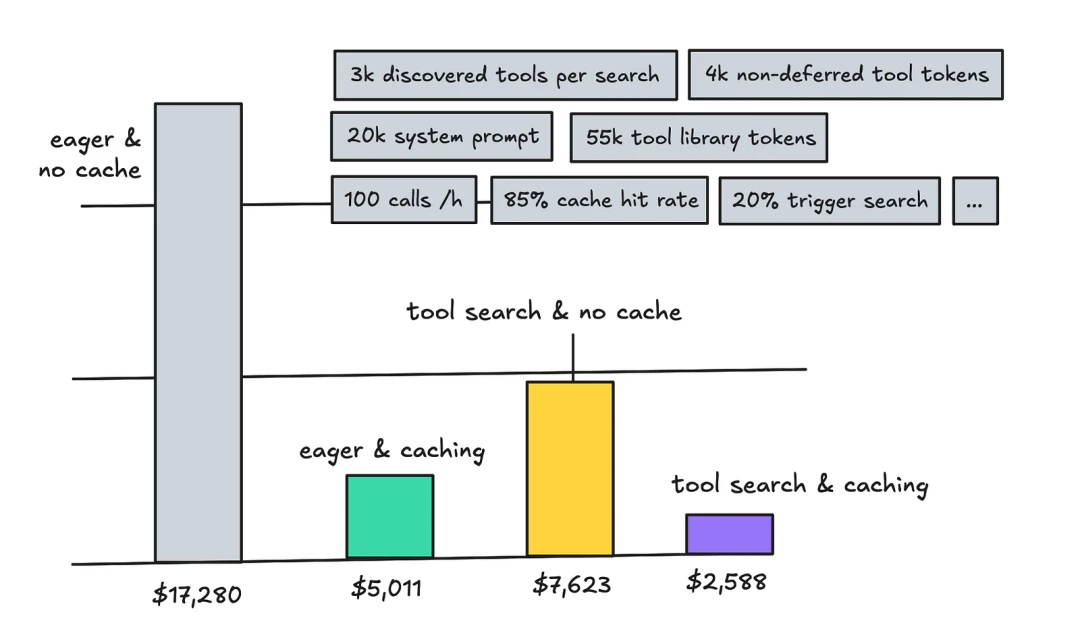
Anthropic’s Advanced Tool Search is a representative approach here: use a search tool to let the LLM find tools on demand instead of defining all tools upfront. Anthropic says they have seen tool definitions of 55K-134K tokens before optimization, and wrong tool selection is a common failure mode at that size.
Others have tested scenarios with 4,000 tools and found weaker results. Handing tool definitions to search also makes debugging harder because you cannot see all intermediate steps.
Core principle: do not expose the agent to a huge, noisy context. Give it a way to narrow scope, and only make it inspect or load tools when needed.
Prompt caching and lazy-loaded tools both reduce cost, but their combined savings are limited. Lazy loading is more valuable for keeping context clean and improving performance. If you only care about cost, choose at least one.
Use Cheaper Models for Cheaper Work
This section covers routing prompts to different models and running subagents with cheaper models. It can reduce token cost, but it comes with quality risk.
Many people say more than 60% of input requests are simple tasks that do not need the strongest model, and especially do not need a reasoning model. ChatGPT uses signals such as conversation type, complexity, tool needs, and explicit intent, such as “think carefully,” for routing. Claude uses description-based delegation and built-in subagents such as Explore.
The idea is simple. Doing it without sacrificing quality is the hard part.
Route by Task Difficulty
Request-level routing means estimating difficulty and intent before seeing any output. The savings can be high, but a wrong choice can damage the whole session.
You need a routing model to decide where each request goes. We do not know exactly what signals OpenAI uses for routing, but you have probably felt the frustration of being delegated to a weaker model when you wanted something stronger.
The open-source community has useful references. RouteLLM from LMSYS, the Berkeley team behind Chatbot Arena, learns from real preference data. It uses standard embeddings plus a tiny routing head, so hosting cost is low. The team reports large cost reductions while preserving most GPT-4 performance.
But the LLMRouterBench paper found that many learned routers barely beat simple baselines such as keyword or heuristic routing, embedding nearest neighbor, or kNN-style routing. These routers may not be especially good at guessing difficulty, so the improvement over simple methods can be limited. People have not abandoned routing, but it is not guaranteed money on the table.
Start With a Cheap Model, Then Cascade on Low Confidence
Instead of guessing whether a prompt is simple or hard, let the cheap model try first, then decide whether to keep the answer or escalate.
Google’s Speculative Cascades framework follows this pattern: use a small model first for speed and cost, and call the large model only when needed. The method has the cheap model generate an answer, then uses a lightweight judge to check confidence, for example by looking at token probability distributions, entropy, or semantic alignment.
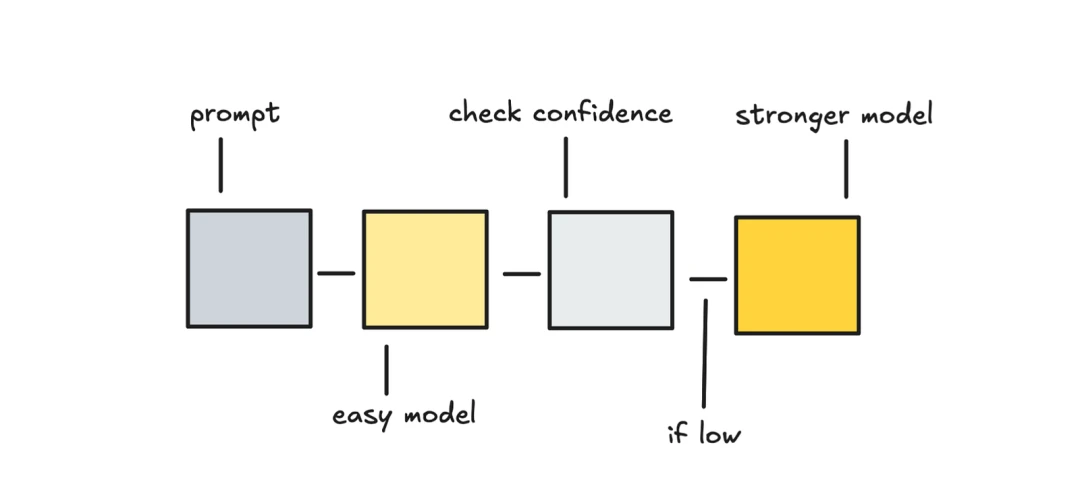
This idea is attractive. Prompt difficulty is often hard to predict, while answer quality is easier to judge once an answer exists. Verification latency can be kept under 20ms. The condition is that most questions must actually be answerable by the simple model, because escalated requests pay for two calls.
CascadeFlow claims 69% cost savings while preserving 96% quality against GPT-5, but its test prompts had verifiable benchmark answers, such as math and multiple-choice questions. Small models often make confident mistakes. Early deployments should use conservative thresholds and escalate more often, which inevitably raises cost.
If the workload fits, cascades may cut cost by 50%, but quality risk remains.
Delegate to Subagents
Subagents delegate work to isolated agents, sometimes using smaller models. That is another form of routing. The savings are less dramatic than routing, but the pattern is worth understanding.
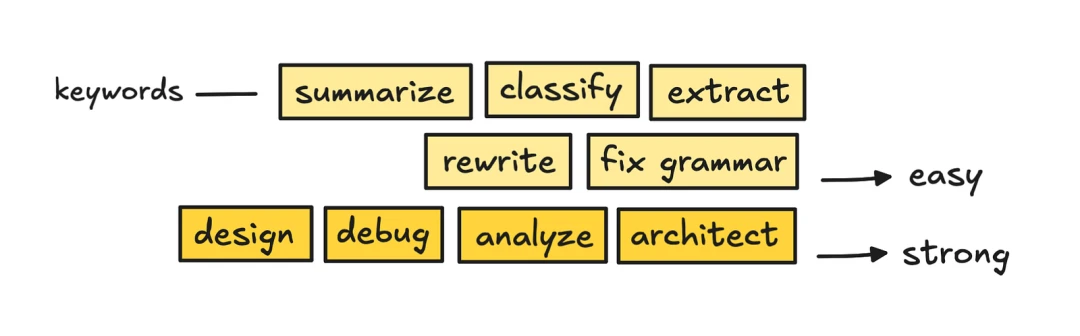
Claude Code has built-in subagents. The Explore subagent explicitly uses Haiku for codebase search and exploration. The main Claude session also delegates by description matching, though users do not see that directly. But the orchestrator usually remains in the loop for planning, synthesis, and retries, so savings are smaller than pure routing. A rough estimate is about 11% savings compared with a no-routing setup.
Keep Context Clean
Good context engineering is often about performance, but it also matters for cost efficiency. Agents keep accumulating junk: tool outputs, logs, repeated observations, old plans, stale attempts, duplicated state. People building agents for the first time tend to put every result into the main agent’s working state.
Bad active context looks like this:
[system rules] [project rules] [user task]
grep output: 2,000 lines | file read: 900 lines
test log: 1,300 lines | retry log | repeated reads
dead-end reasoning | more logs | more logs
OpenClaw and Claude Code users have both complained about context bloat. Adding things is always easier than cleaning them up.
Build a State Pipeline
This is a two-layer problem. You need to keep content clean as it enters context, not only compress it after the fact. That becomes unglamorous engineering work.
Raw outputs can be archived, while only the useful parts enter active context. Tool-output bloat is the main enemy. By default, tools should emit less noise.
Good active context looks more like this:
[system rules] [project rules] [user task] [current working state]
Keep:
+ auth flow is in auth.ts + session.ts
+ bug appears only on refresh path
+ failing test: session_refresh_keeps_user
+ likely refresh overwrite issue
+ relevant files: auth.ts, session.ts, auth.test.ts
Discard:
- raw grep results
- full test logs
- repeated file dumps
- dead-end retries
Some context can have lifecycle rules or expiration. When it is time to compress, that makes it easier to decide what is useful to the LLM. Anthropic has also pointed out that compression needs to preserve architectural decisions, unresolved bugs, and implementation details.
LangChain’s autonomous compression approach lets the agent decide when to compress instead of waiting until context is already bloated. Teams are also starting to evaluate compression as a systems problem, with benchmarks and agent-specific strategies, rather than generic summarization tricks.
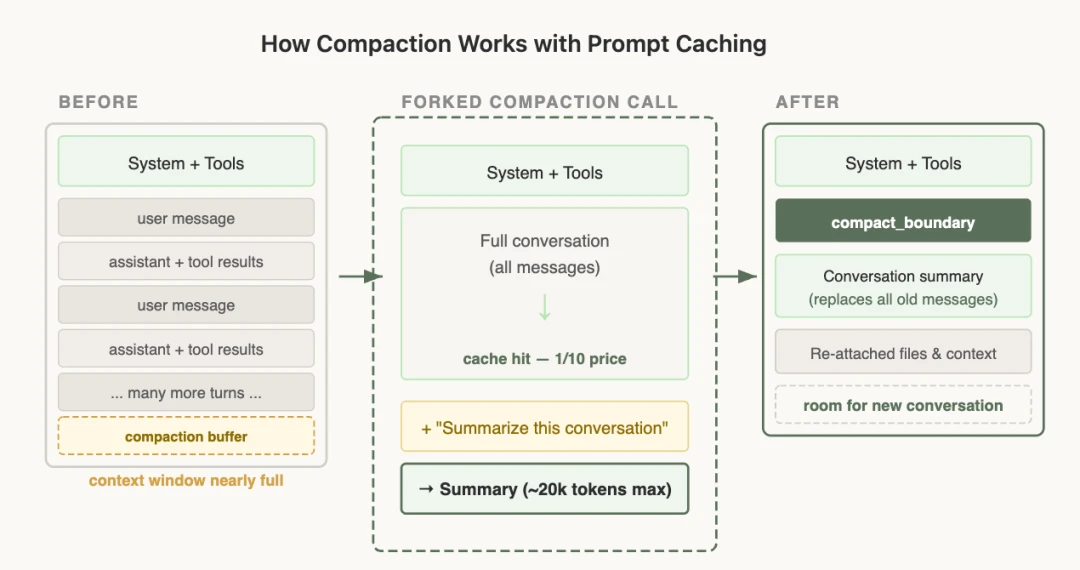
Compression itself must be cache-safe. A common mistake is doing compression with a separate API call that uses a different system prompt, such as “summarize this,” without tools. The prefix differs from the first token, so the existing cache cannot be used and the whole conversation is billed at full price. The longer the conversation, meaning the more it needs compression, the more expensive that call becomes. The correct approach is to use the exact same system prompt, user context, and tool definitions as the parent conversation, prepend the parent messages, and append the compression prompt as a new user message at the end. From the API’s perspective, the request is almost identical to the parent conversation’s last request. The cached prefix is reused, and the only new tokens are the compression prompt itself. Remember to reserve a compression buffer so the context window has enough room for the compression instruction and the summary output.
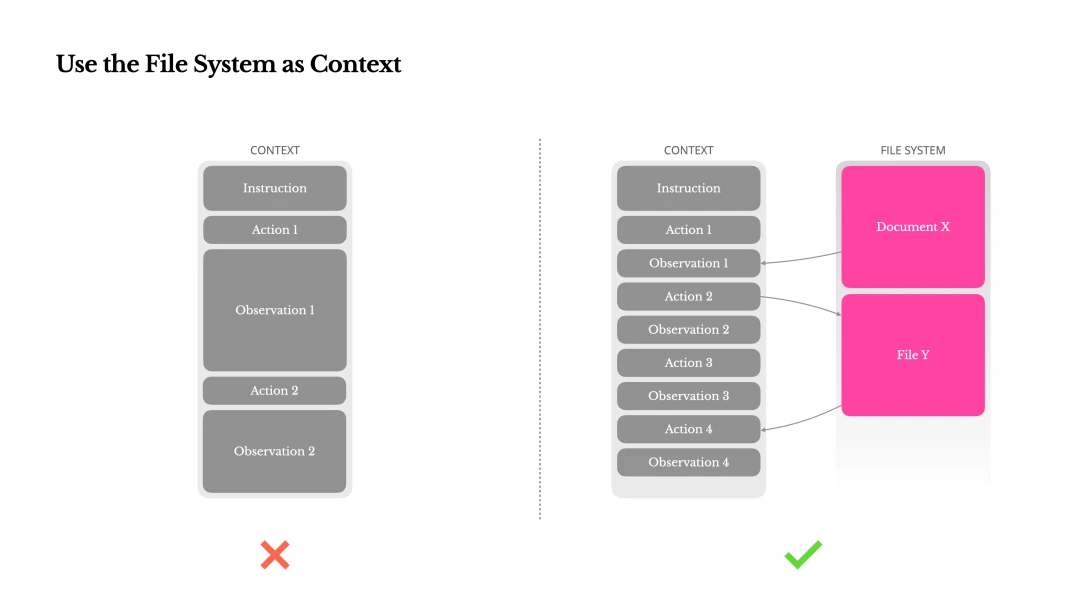
The file system is the ultimate context. Manus treats the file system as the ultimate context: unbounded in size, persistent by default, and directly operable by the agent. The model learns to write and read files on demand, using the file system not only as storage but also as structured external memory. Its compression strategy is designed to be recoverable. If a URL is preserved, webpage content can be removed from context. If a document path remains in the sandbox, the document content can be omitted. The agent can shorten context without permanently losing information.
Jia et al. show that 6x compression can reduce token budget by 51.8-71.3%, while improving problem-solving rate on SWE-bench Verified by 5.0-9.2%. So compression is not only about cost. It can improve performance.
On cost, removing junk can free 30-70% of the context and save money in the same proportion. For a 10K context window and 100K runs, cleaning up 30-50% saves about $1,500. At a 40K context window, the savings reach about $6,000. But when using very small cheap models, the compression call itself may cost more than it saves.
The benefit of context cleanup is that it does not trade away quality. Unlike semantic cache or routing, it does not inherently add quality risk. Done well, it is pure upside. The problem is the engineering work.
Four Directions, No Silver Bullet
- Prompt caching: use it when a long system prompt stays unchanged across repeated calls. It is the fastest win.
- Semantic cache: consider it for general Q&A bots that need lower cost. It takes more engineering.
- Model routing: test it when you need to handle both simple and complex questions. Evaluate the quality risk.
- Context cleanup: this is the basic discipline when you do not want to send unnecessary tokens. It is pure upside, but it takes engineering.
Which optimization are you using now? How much has your bill dropped? What traps have you hit?
References
- Ida Silfverskiöld, “Agentic AI: How to Save on Tokens,” Towards Data Science, 2026.
- Yichao “Peak” Ji, “Context Engineering for AI Agents: Lessons from Building Manus,” Manus Blog, 2025.
- Thariq Shihipar, “Lessons from Building Claude Code: Prompt caching is everything,” Claude Blog, 2026.